Cut Column
This transform will slice each string value in a specific column based on the index numbers. This is applicable only for string columns in a dataset.
tags: [“Data Preparation”]
Parameters
The table gives a brief description about each parameter in Cut Column transform.
- Name:
By default, the transform name is populated. You can also add a custom name for the transform.
- Input Dataset:
The file name of the input dataset. You can select the dataset that was uploaded from the drop-down list. (Required: True, Multiple: False)
- Output Dataset:
The file name with which the output dataset is created after slicing each string value based on the given index range from the input dataset. (Required: True, Multiple: False)
- Column:
The column name on which the cut column transform must be performed. (Required: True, Multiple: True, Datatypes: [“STRING”], Options: [‘FIELDS’], Datasets: [‘df’])
- First character index:
The index value of the first character from which the slicing should happen. (Required: True, Multiple: False, Datatypes: [‘LONG’], Options: [‘CONSTANT’])
:Last character index : The index value of the last character up to which the slicing should happen and return the range of characters or part of string. (Required: True, Multiple: False, Datatypes: [‘LONG’], Options: [‘CONSTANT’])
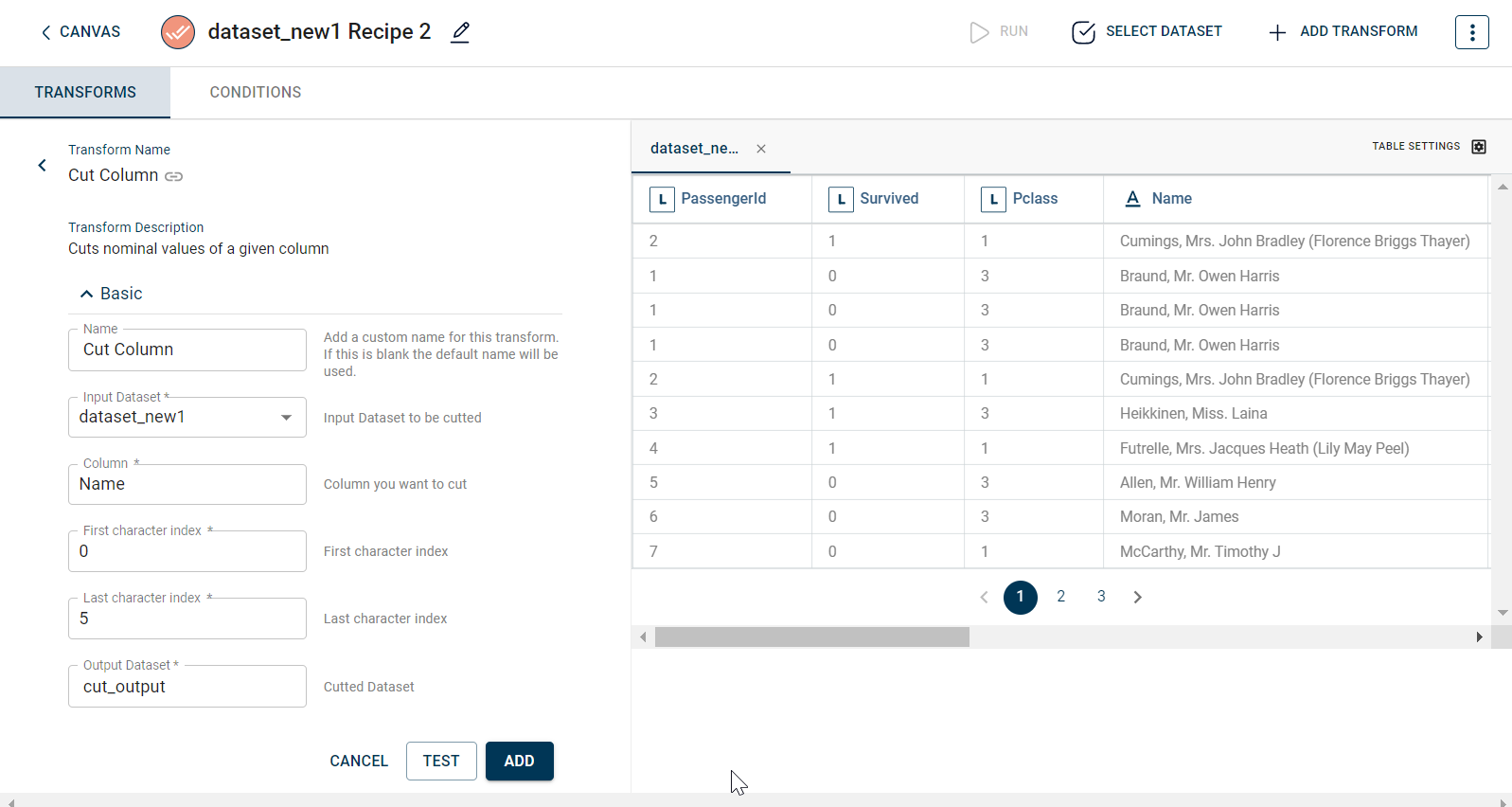
The sample input for this transform looks as below:
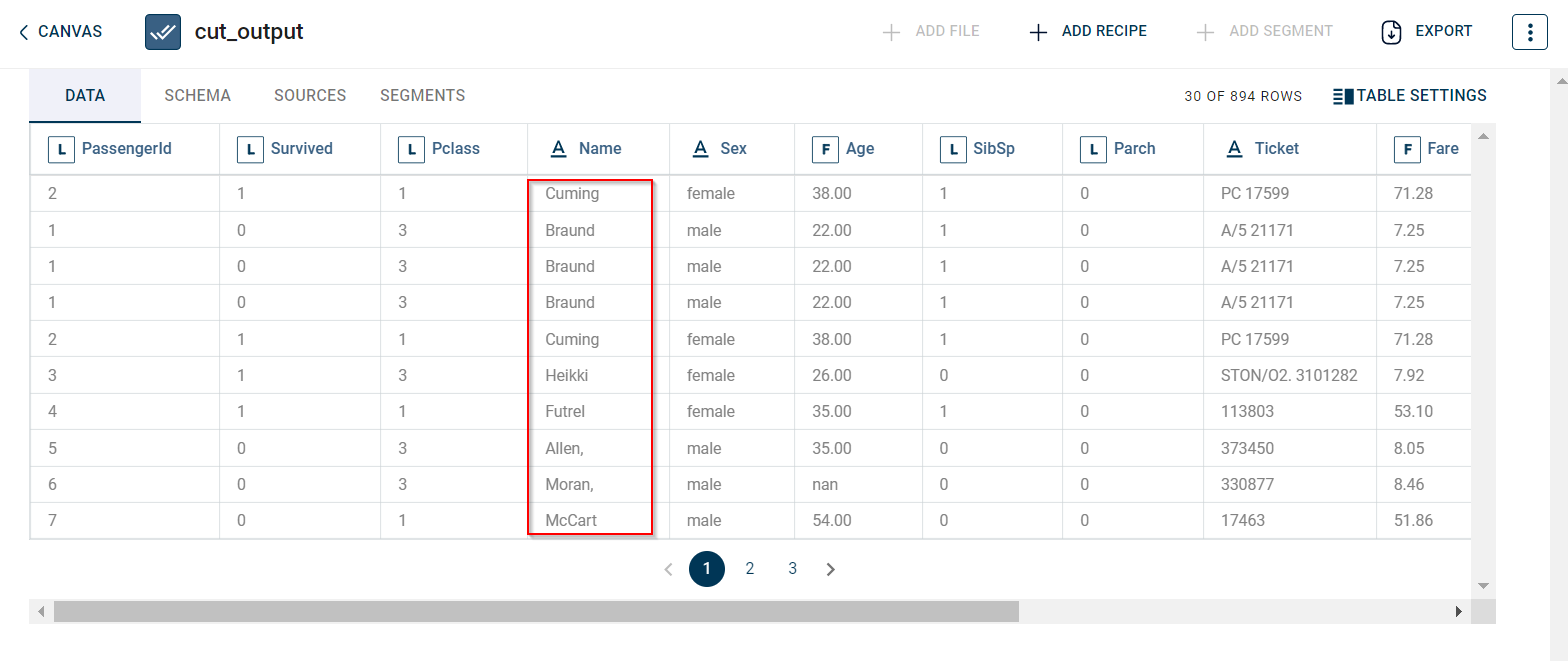
The output after running the Cut Column transform on the dataset appears as below:
How to use it in Notebook
The following is the code snippet you must use in the Jupyter Notebook editor to run the Cut Column transform:
template=TemplateV2.get_template_by('Cut Column')
recipe_Cut_Column= project.addRecipe([car_data, employee_data, temperature_data, only_numeric], name='Cut Column')
transform=Transform()
transform.templateId = template.id
transform.name='Cut Column'
transform.variables = {
'input_dataset':'car',
'output_dataset':'car_cutted',
'col':"CarName",
'i':0,
'j':4}
recipe_Cut_Column.add_transform(transform)
recipe_Cut_Column.run()
Requirements
pandas