One hot encoding
This transform returns a new dataset with each categorical value converted into a new binary column. However, the categories are formed based on the cardinality cutoff value. This cardinality cut off is applicable for all columns in a dataset. For instance, the column has five unique values and the cardinality cutoff value is 5, this divides these values into five different columns. Each row in the output dataset will have a 1 in the column corresponding to the categorical value and 0 in all columns.
Parameters
The table gives a brief description about each parameter in N Root Column transform.
- Name:
By default, the transform name is populated. You can also add a custom name for the transform.
- Input Dataset:
The file name of the input dataset. You can select the dataset that was uploaded from the drop-down list. (Required: True, Multiple: False)
- Cardinality Cutoff:
The cut off value is a threshold value to consider a column as a category or not.
- If Keep Original Columns:
Indicates whether the original columns must be kept as is after categorization or should be appended in the output with the categorized columns.
- Target column:
The target column on which predictions are made. This should be kept intact in feature engineering.
- Output Dataset:
The file name with which the output dataset is created. This file contains the new columns, one for each unique value in the columns. (Required: True, Multiple: False)
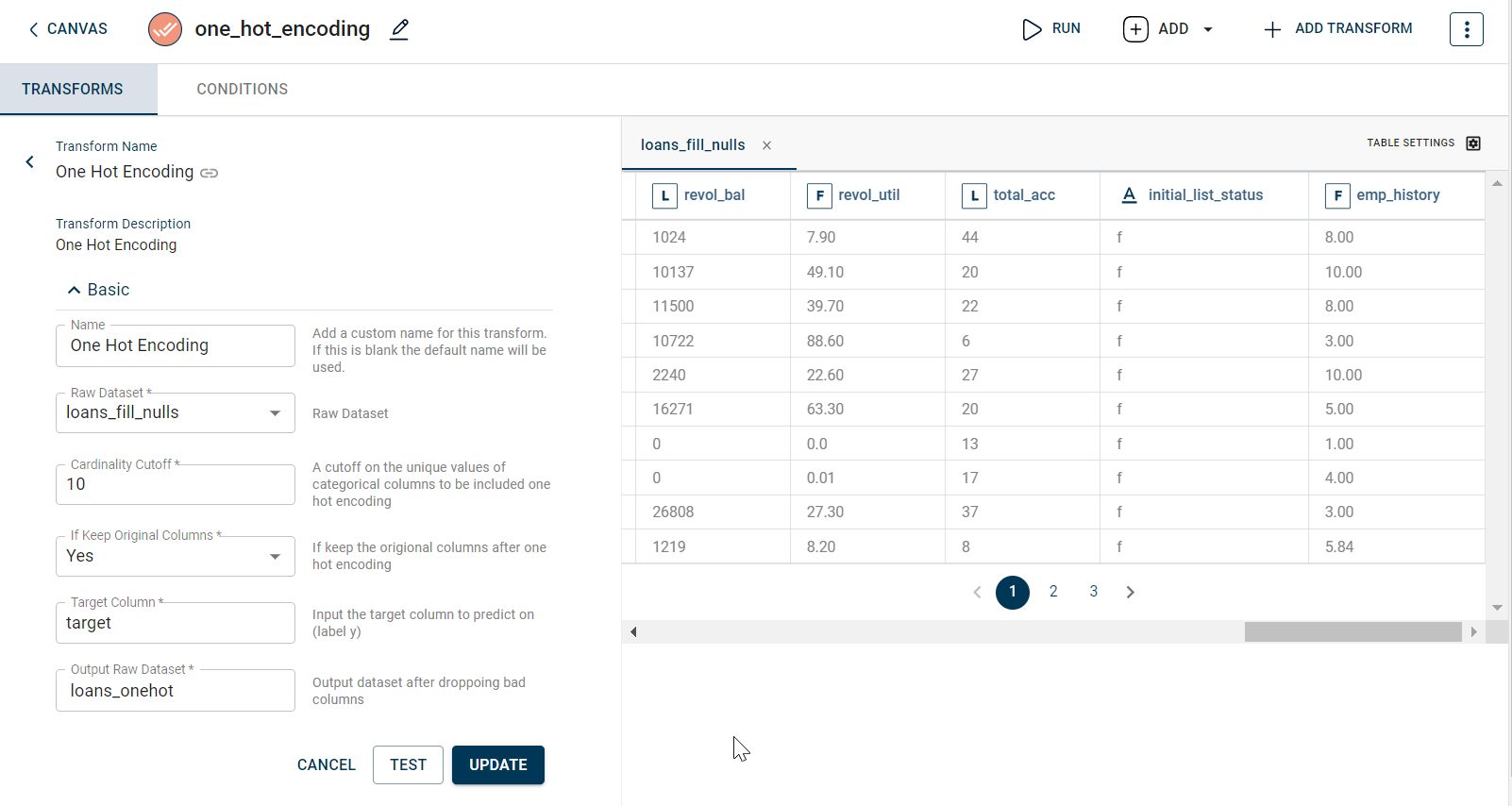
Below is the screenshot with sample input data for this transform.
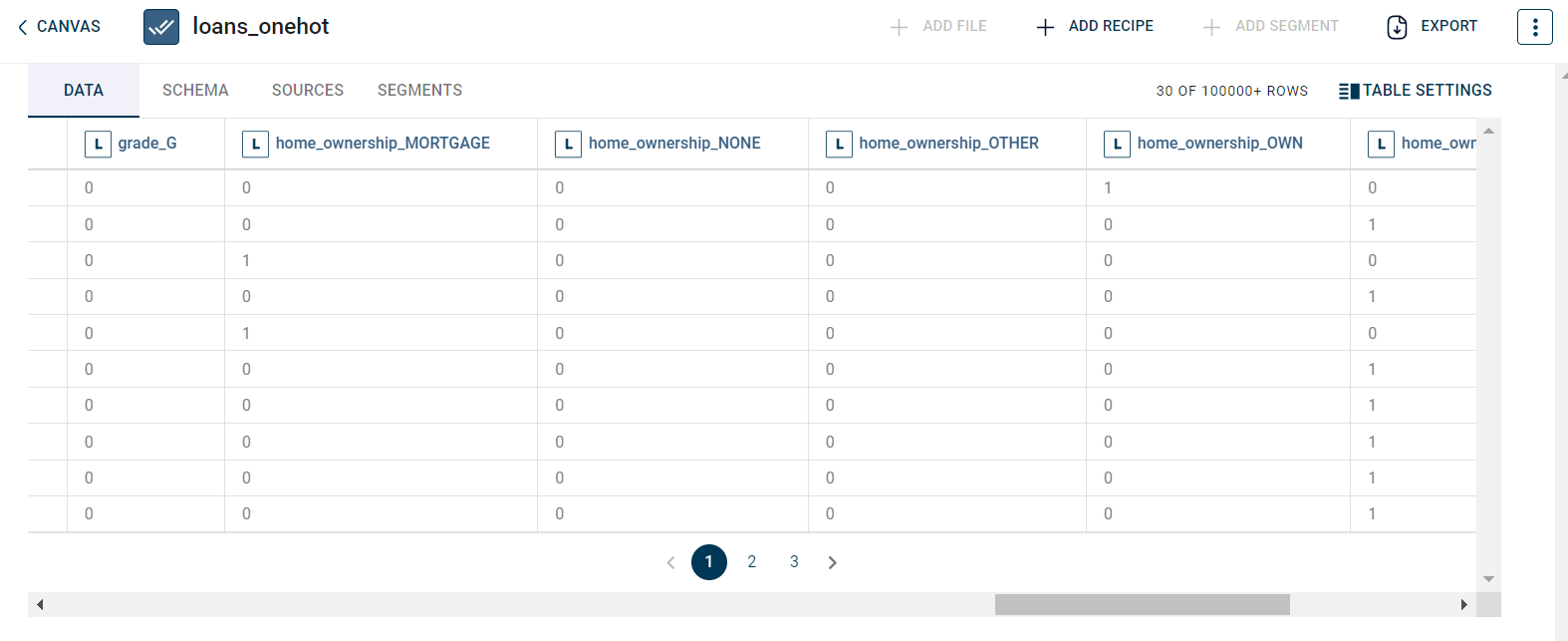
The output or result after running the One Hot encoding transform looks as below:
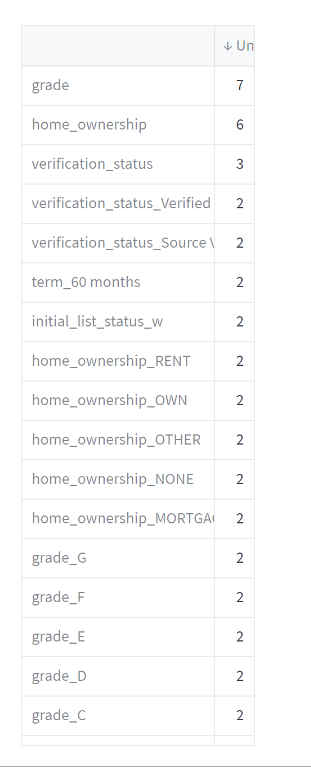
The dashboard displayed with the list of unique values in each column of a dataset.
How to use it in Notebook
The following is the code snippet you must use in the Jupyter Notebook editor to run the One hot encoding transform:
Requirements
scikit-learn pandas