Principal Component Analysis
This transform is used for reducing the number of features in a dataset, while preserving the important information. This feature engineering transform is applicable only to numerical data.
tags: [“Data Preparation”]
Parameters
The table gives a brief description about each parameter in the Principal Component Analysis transform.
- Name:
By default, the transform name is populated. You can also add a custom name for the transform.
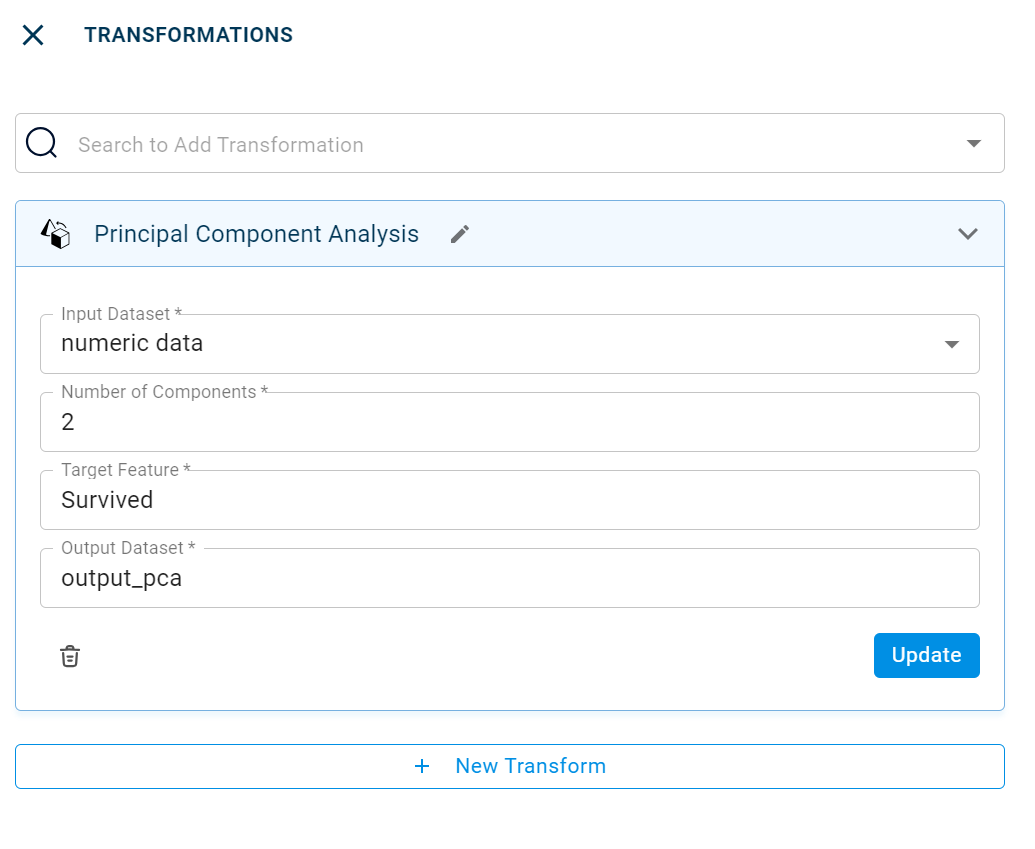
- Input Dataset:
The file name of the input dataset. You can select the dataset that was uploaded from the drop-down list. (Required: True, Multiple: False)
- Output Dataset:
The file name with which the output dataset is created. (Required: True, Multiple: False)
- Number of Components:
The number of principal components. (Required: True, Multiple: False, Datatypes: [“LONG”], Options: [‘CONSTANT’])
- Target Feature:
The target feature or column of the Dataset. (Required: True, Multiple: False, Options: [‘FIELDS’], Datasets: [‘df’])
The sample input for this transform looks as shown in the screenshot:
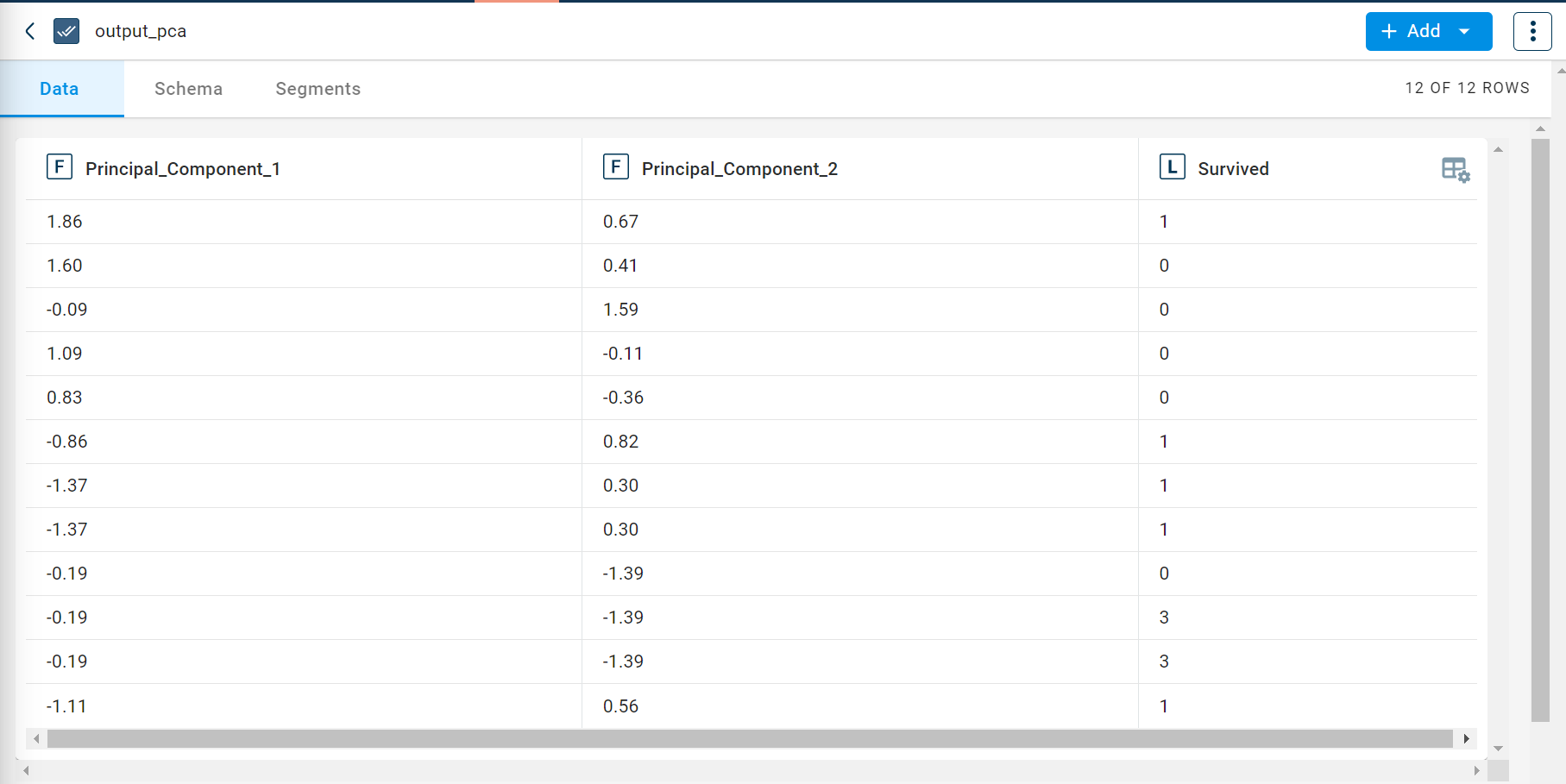
The output after running the Principal Component Analysis transform on the dataset appears as below:
How to use it in Notebook
The following is the code snippet you must use in the Jupyter Notebook editor to run the Principal Component Analysis transform:
template=TemplateV2.get_template_by('Principal Component Analysis')
recipe_Principal_Component_Analysis= project.addRecipe([car_data, employee_data, temperature_data, only_numeric], name='Principal Component Analysis')
transform=Transform()
transform.templateId = template.id
transform.name='Principal Component Analysis'
transform.variables = {
'input_dataset':'only_numeric',
'output_dataset':'principal_comp',
'n':1,
'target':"Age"}
recipe_Principal_Component_Analysis.add_transform(transform)
recipe_Principal_Component_Analysis.run()
Requirements
scikit-learn pandas